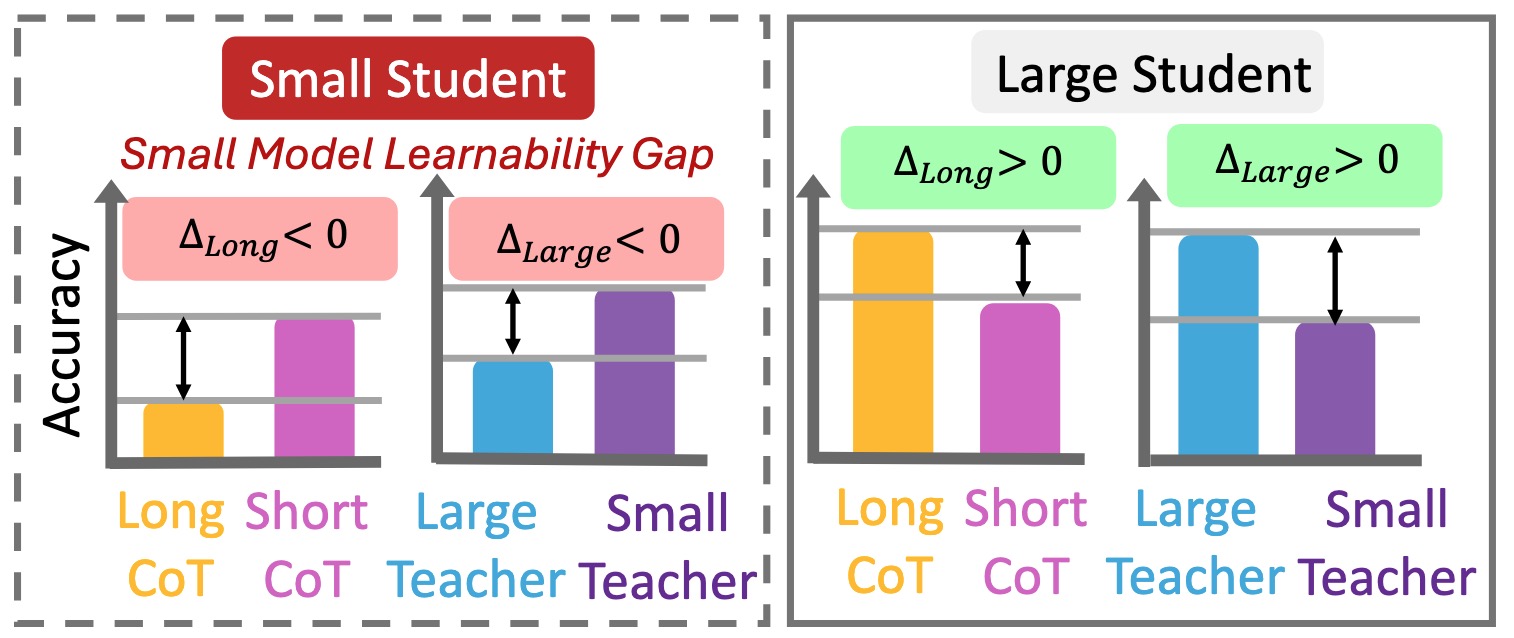
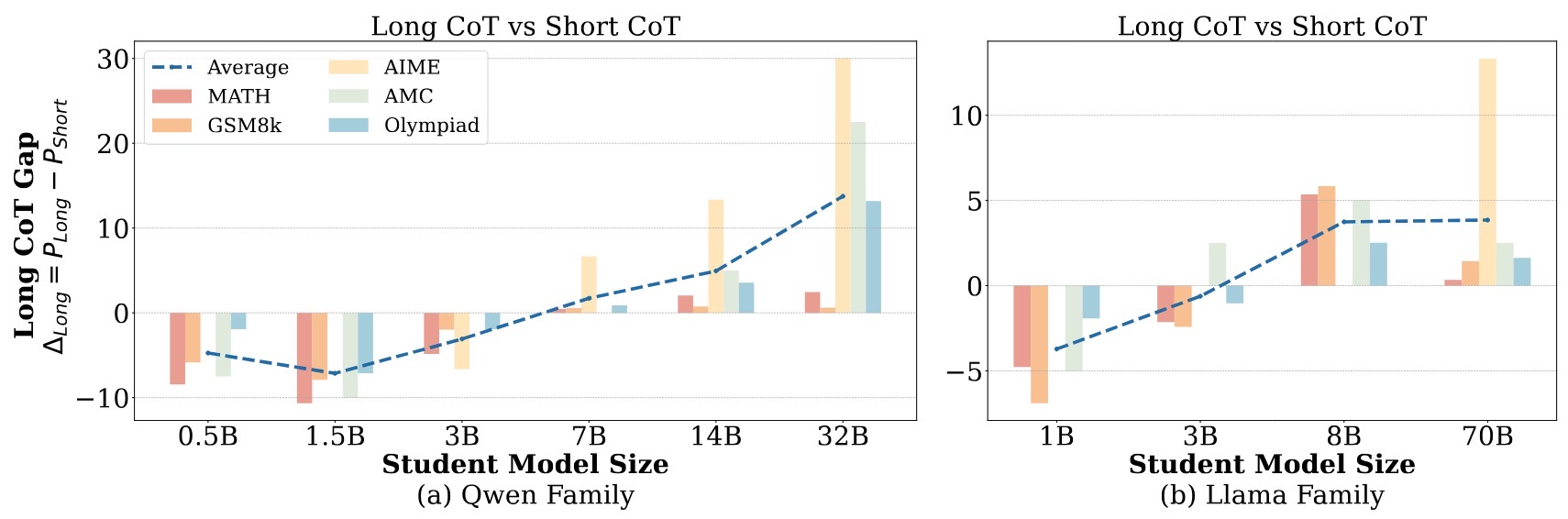
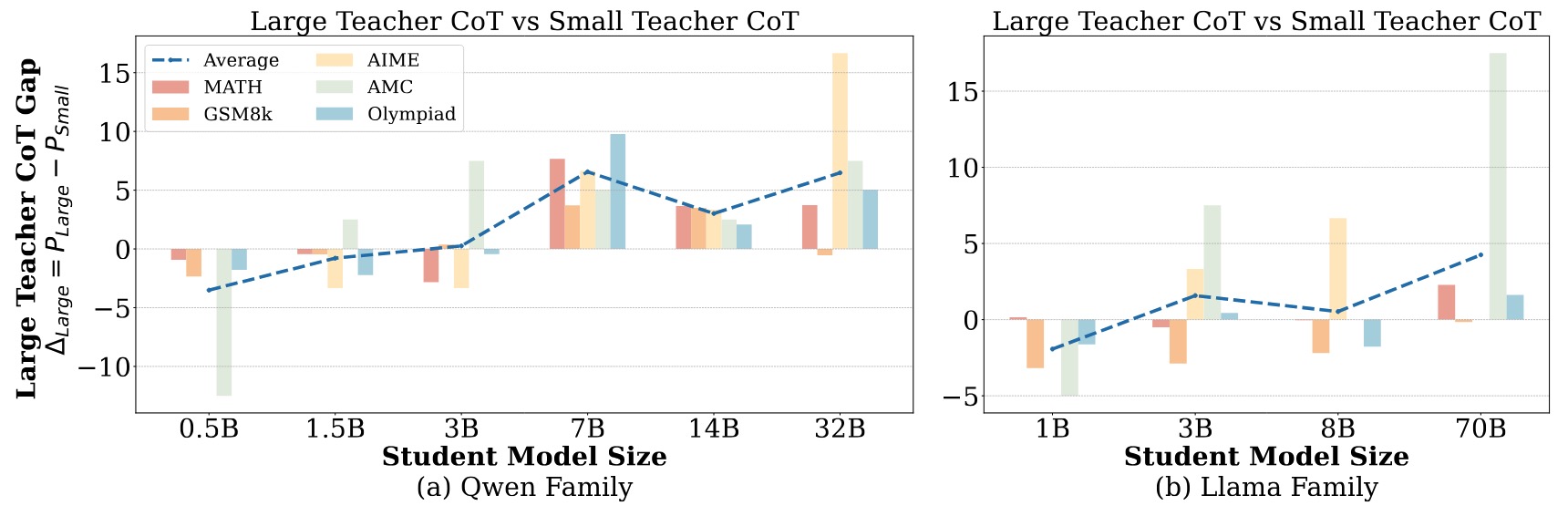
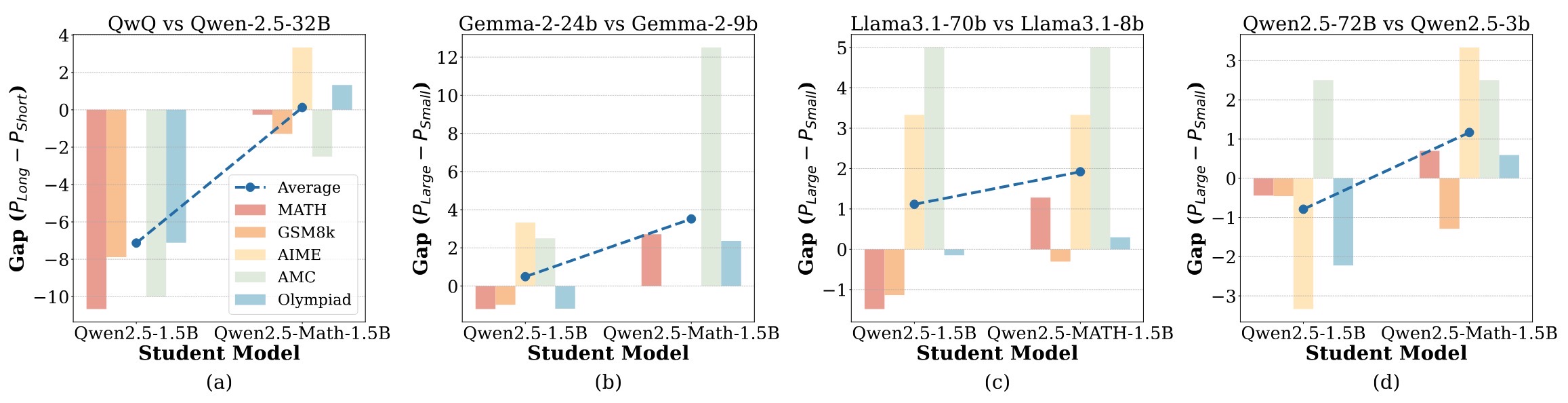
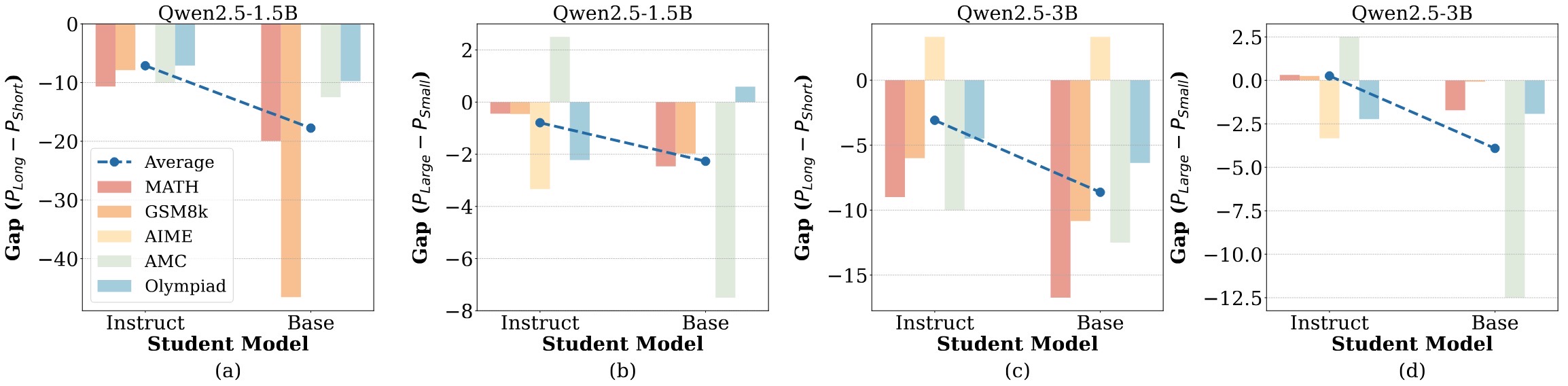
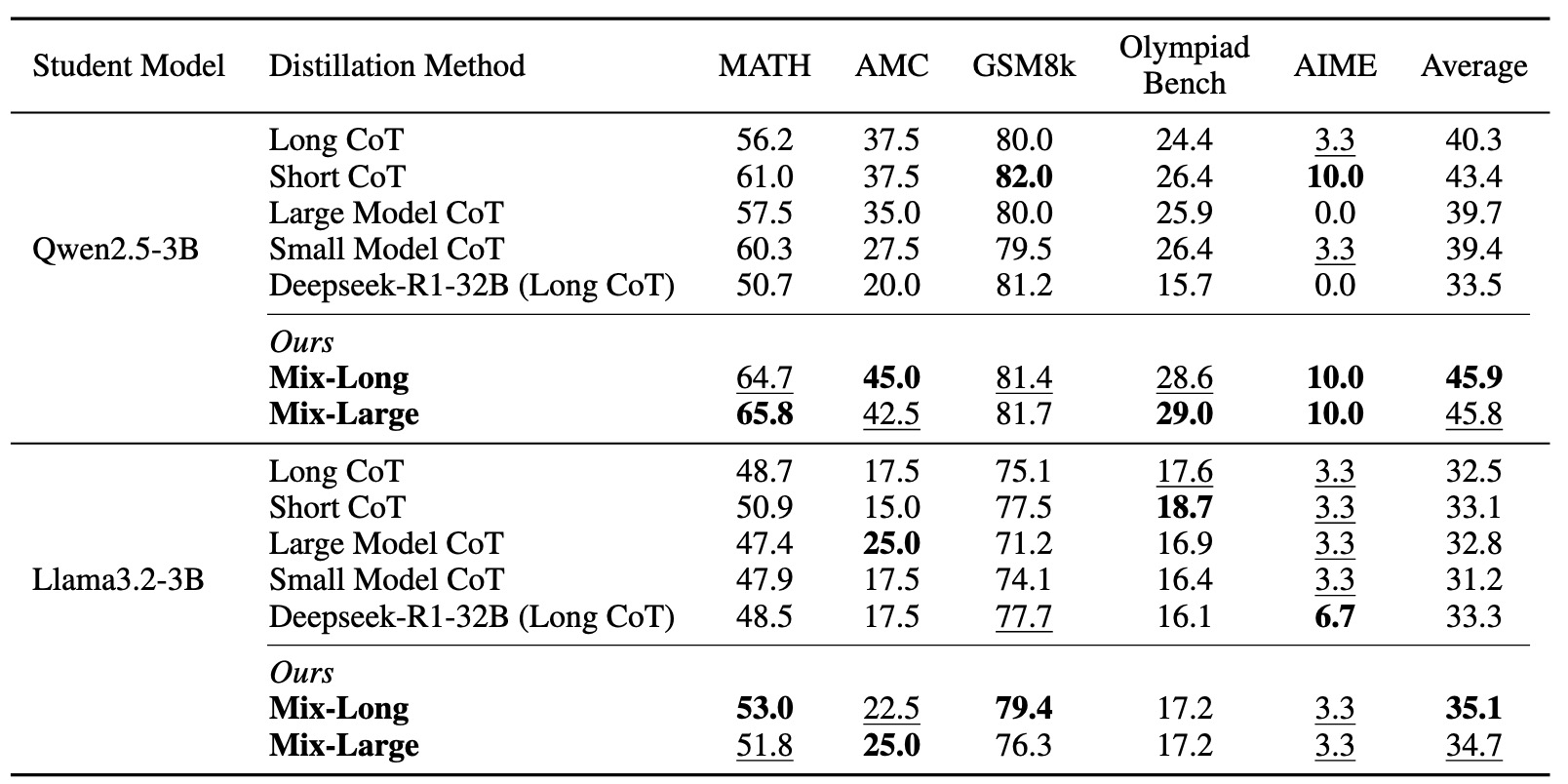
We reveal that small student models (≤3B parameters) do not consistently benefit from long CoT reasoning or distillation from large teacher models. Instead, they perform better when fine-tuned on shorter CoT reasoning or distilled from smaller teachers, which better aligns with their intrinsic learning capacity. We term this phenomenon as the Small Model Learnability Gap.
Small Model Learnability Gap